Robot Fine-Tuning Made Easy: Pre-Training Rewards and Policies for Autonomous Real-World Reinforcement Learning
Jingyun Yang* Max Sobol Mark* Brandon Vu Archit Sharma Jeannette Bohg Chelsea Finn
*Equal Contribution Stanford University
Abstract
The pre-train and fine-tune paradigm in machine learning has had dramatic success in a wide range of domains because the use of existing data or pre-trained models on the Internet enables quick and easy learning of new tasks. We aim to enable this paradigm in robotic reinforcement learning, allowing a robot to learn a new task with little human effort by leveraging data and models from the Internet. However, reinforcement learning often requires significant human effort in the form of manual reward specification or environment resets, even if the policy is pre-trained. We introduce RoboFuME, a reset-free fine-tuning system that pre-trains a multi-task manipulation policy from diverse datasets of prior experiences and self-improves online to learn a target task with minimal human intervention. Our insights are to utilize calibrated offline reinforcement learning techniques to ensure efficient online fine-tuning of a pre-trained policy in the presence of distribution shifts and leverage pre-trained vision language models (VLMs) to build a robust reward classifier for autonomously providing reward signals during the online fine-tuning process. In a diverse set of five real robot manipulation tasks, we show that our method can incorporate data from an existing robot dataset collected at a different institution and improve on a target task within as little as 3 hours of autonomous real-world experience. We also demonstrate in simulation experiments that our method outperforms prior works that use different RL algorithms or different approaches for predicting rewards.
Video
Motivation
The pre-train and fine-tune paradigm in machine learning has had dramatic success in a wide range of domains because the use of existing data and pre-trained models enables quick and easy learning of new tasks. The goal of this paper is to enable this paradigm in robot reinforcement learning.
Method Overview
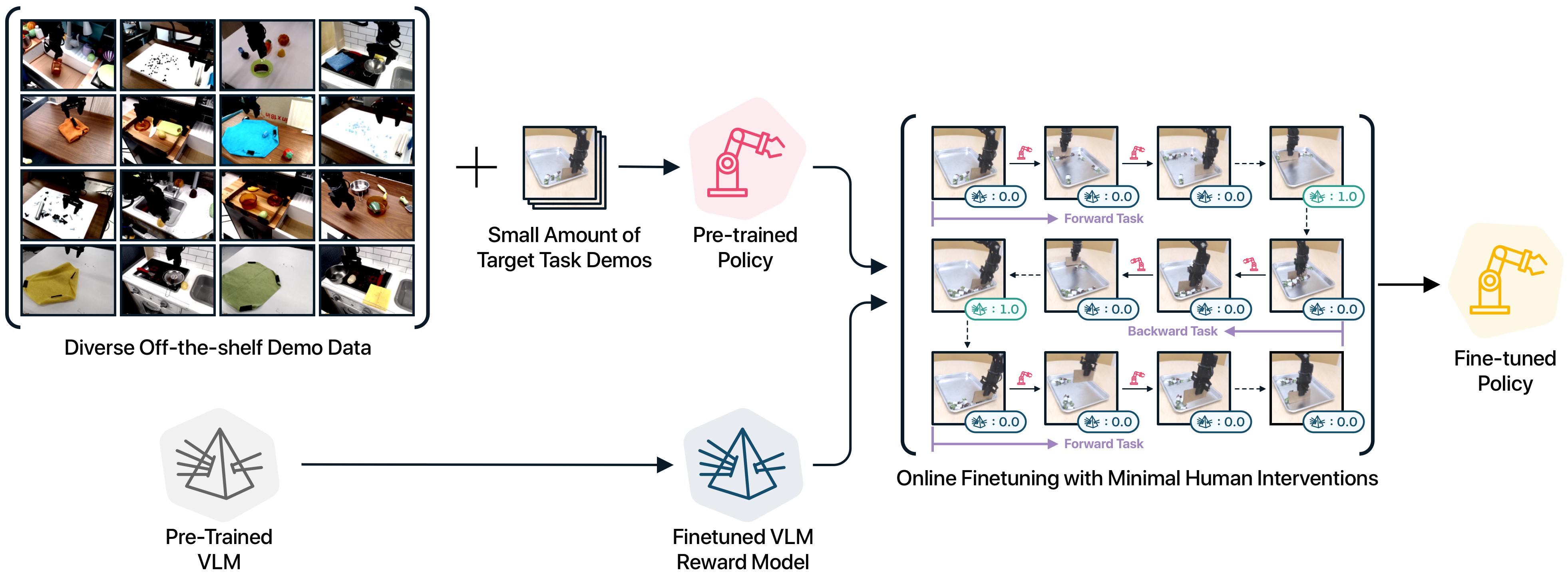
We propose a system that enables autonomous and efficient real-world robot learning by first pre-training a VLM reward model and a multi-task policy from diverse off-the-shelf demonstration datasets and then fine-tuning the pre-trained policy online with the VLM reward model.
Real Robot Experiments
Tasks
We test our system on five different manipulation tasks: candy sweeping, cloth folding, object covering, pot lid, and pot pick-and-place.
Candy Sweeping
Cloth Folding
Object Covering
Pot Lid
Pot PNP
Prior Data
We use diverse prior demonstration data from the Bridge V2 dataset, which was collected at a different institution. For each task, we pick about 1,000 relevant trajectories in the dataset as prior data for the agent.
Target Task Demonstrations
In addition to the prior data, we spend 30 minutes to collect 50 successful demos for both the forward and backward target tasks, as well as 10 minutes of failure demos for both tasks. Below, we show sample demos that we collected for the candy sweeping task.
Successful Forward Demos
Successfull Backward Demos
Failure Forward Demos
Failure Backward Demos
Autonomous Fine-tuning
We pre-train a reinforcement learning policy from both the prior data and the target demonstration data using an offline RL algorithm. Then, we rollout the policy to perform the forward and backward tasks alternatively while updating the policy with the VLM reward model as reward feedback. Since the policy is able to reset the environment after trying out the task, the fine-tuning phase can run with minimal human interventions. Below, we show timelapses of the fine-tuning stage for the candy sweeping and cloth covering tasks.
Candy Sweeping
Cloth Covering
Quantitative Results
Our method significantly improves over both offline-only and BC performance after 30k steps of online interaction (2-4 hours).

Evaluation Videos
Below, we show evaluation videos for all 5 tasks. Please select tab to see evaluation videos for the corresponding task.
BC
Ours (Offline)
Ours (FT 3 Hours)
BC
Ours (Offline)
Ours (FT 3 Hours)
BC
Ours (Offline)
Ours (FT 3 Hours)
BC
Ours (Offline)
Ours (FT 3 Hours)
BC
Ours (Offline)
Ours (FT 3 Hours)
Simulation Experiments
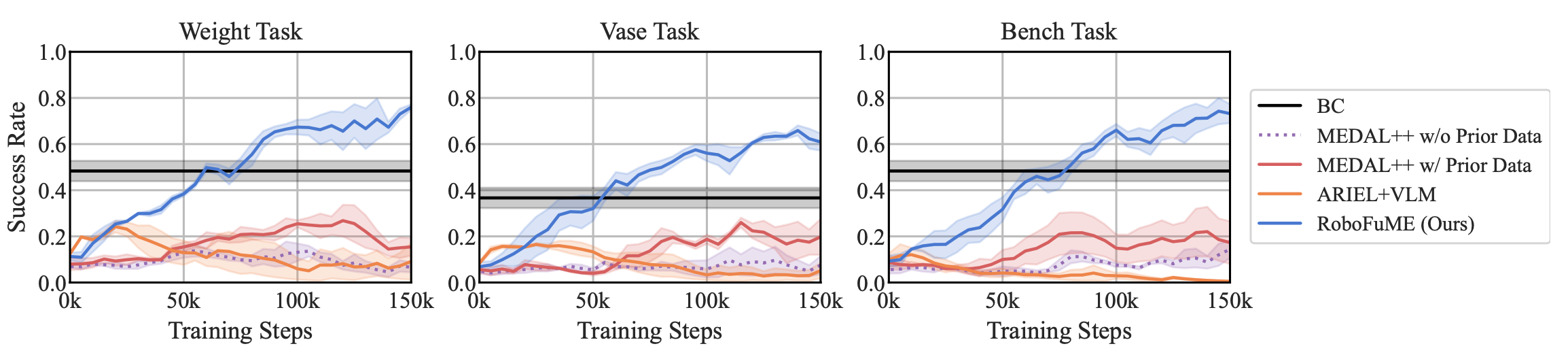
We use a suite of three simulated robotic manipulation environments to ablate contributions of different components of our algorithm.
Put metal weight from
table to bin
Put wood bench from
table to bin
Put yellow vase from
table to bin
We report the success rate over the course of training, averaged over three seeds. Our method RoboFuME outperforms BC, ARIEL+VLM, and MEDAL++ consistently on all three domains.
BibTeX
@misc{
yang2023robot,
title={Robot Fine-Tuning Made Easy: Pre-Training Rewards and Policies for Autonomous Real-World Reinforcement Learning},
author={Jingyun Yang and Max Sobol Mark and Brandon Vu and Archit Sharma and Jeannette Bohg and Chelsea Finn},
year={2023},
eprint={2310.15145},
archivePrefix={arXiv},
primaryClass={cs.RO}
}